Définition
Un système de gestion de base de données est un logiciel qui permet de gérer plusieurs bases de données.
Lorsque le SGBD est une base de données relationnelle, il peut avoir l'acronyme SGBDR.
Le SGBD permet de faire une abstraction entre le fonctionnement interne de la technologie et les requêtes. Les logiciels qui utilisent une base de données dans un SGBD effectuent uniquement des échanges de communication. Il s'agit d'une communication client-serveur. Le serveur (SGBD) reçoit la requête et retourne le résultat au client (Logiciel). Les librairies à installer dans le logiciel client sont uniquement une librairie de communication.
SQLite n'est pas un SGBD, le logiciel qui l'utilise doit avoir la logique du fonctionnement de SQLite à l'intérieur de celui-ci. La librairie SQLite contient toute la logique de fonctionnement pour interagir correctement avec le fichier.
Un SGBD est installé en mode service dans un environnement de production. Les bases de données doivent être accessibles en tout temps.
Objectif du SGBD
- Indépendance physique (1)
Plus besoin de travailler directement sur les fichiers physiques (tels qu’ils sont enregistrés sur disque). Un SGBD nous permet de décrire les données et les liens entre elles d’une façon logique sans nous soucier du comment cela va se faire physiquement dans les fichiers. On parle alors d’image logique de la base de données (ou aussi description logique ou conceptuelle ou encore de schéma logique). Ce schéma est décrit dans un modèle de données par exemple le modèle de tables, appelé le modèle relationnel. - Indépendance physique (2)
La manipulation des données doit être facilitée en travaillant directement sur le schéma logique. On peut insérer, supprimer, modifier des données directement sur l’image logique. Le SGBD va s’occuper de faire le travail sur les fichiers physiques. - Indépendance logique
Un même ensemble de données peut être vu différemment par des utilisateurs différents. Toutes ces visions personnelles des données doivent être intégrées dans une vision globale. - Manipulations des données par des non-informaticiens
Il faut pouvoir accéder aux données sans savoir programmer ce qui signifie des langages « quasi naturels ». - Efficacité des accès aux données
Ces langages doivent permettre d’obtenir des réponses aux interrogations en un temps « raisonnable ». Ils doivent donc être optimisés et, entre autres, il faut un mécanisme permettant de minimiser le nombre d’accès disques. Tout ceci, bien sûr, de façon complètement transparente pour l’utilisateur. - Administration centralisée des données
Des visions différentes des données (entre autres) se résolvent plus facilement si les données sont administrées de façon centralisée. - Cohérence des données
Les données sont soumises à un certain nombre de contraintes d’intégrité qui définissent un état cohérent de la base. Elles doivent pouvoir être exprimées simplement et vérifiées automatiquement à chaque insertion, modification ou suppression de données, par exemple :- l’âge d’une personne supérieur à zéro
- Salaire supérieur à zéro
Dès que l’on essaie de saisir une valeur qui ne respecte pas cette contrainte, le SGBD le refuse. - Non-redondance des données
Afin d’éviter les problèmes lors des mises à jour, chaque donnée ne doit être présente qu’une seule fois dans la base. - Partage des données
Il s’agit de permettre à plusieurs utilisateurs d’accéder aux mêmes données au même moment.
Si ce problème est simple à résoudre quand il s’agit uniquement d’interrogations et quand on est dans un contexte mono-utilisateur, cela n’est plus le cas quand il s’agit de modifications dans un contexte multi-utilisateur.
Il s’agit alors de pouvoir :- Permettre à deux (ou plus) utilisateurs de modifier la même donnée « en même temps »;
- Assurer un résultat d’interrogation cohérent pour un utilisateur consultant une table pendant qu’un autre la modifie.
- Sécurité des données
Les données doivent pouvoir être protégées contre les accès non autorisés. Pour cela, il faut pouvoir associer à chaque utilisateur des droits d’accès aux données. - Résistance aux pannes
Que se passe-t-il si une panne survient au milieu d’une modification, si certains fichiers contenant les données deviennent illisibles?
Les pannes, bien qu’étant assez rares, se produisent quand même de temps en temps. Il faut pouvoir, lorsque l’une d’elles arrive, récupérer une base dans un état « sain ».
Ainsi, après une panne intervenant au milieu d’une modification deux solutions sont possibles : soit récupérer les données dans l’état dans lequel elles étaient avant la modification, soit terminer l’opération interrompue.
PostgreSQL
PostgreSQL est un SGBDR libre de droits et multiplateforme. Il peut être utilisé sans aucune contrainte dans des environnements de productions.
L'histoire de PostgreSQL remonte à 1985 avec la réécriture de zéro d'une base de données Ingres. Le nom initial du logiciel était Postgres, comme raccourci de post-Ingres. Lors de l'ajout des fonctionnalités SQL en 1995, Postgres fut renommé Postgres95. Ce nom fut changé à la fin de 1996 en PostgreSQL.
PostgreSQL n'est pas possédé par une compagnie précisément. Toute une communauté de développeurs et d'entreprises maintiennent le projet libre de droit (licence BSD). Cela en fait l'un des SGBDR les plus robustes et populaires.
Pour plus d'information : https://fr.wikipedia.org/wiki/PostgreSQL
Type de données
Un SGBD offre généralement une multitude de types de données, contrairement à SQLite.
Chacun de ces types permet d'avoir une meilleure gestion des données au niveau de l'espace mémoire et de l'uniformité.
Voici une liste des types les plus populaires.
| Type | Description | Équivalent SQLite |
|---|---|---|
| SMALLINT | Entier de 2 octets (-32 768 à 32767) | INTEGER |
| INT INTEGER | Entier de 4 octets (-2 147 483 648 à 2 147 483 648) | INTEGER |
| BIGINT | Entier de 8 octets (-9 223 372 036 854 775 808 à 9 223 372 036 854 775 807) | INTEGER |
| SERIAL | Entier de 4 octets (-2 147 483 648 à 2 147 483 648) auto incrémenté. Ce qui veut dire que la base de données gère l'incrément de la valeur pour nous. CEPENDANT, c'est l'ancienne façon de gérer l'auto-incrément. Il est suggéré d'utiliser GENERATED ALWAYS AS IDENTITY | INTEGER PRIMARY KEY |
| DECIMAL(M,D) NUMERIC(M,D) | Nombre décimal précis. M correspond au nombre total de chiffres et D à la précision. Pour enregistrer un nombre entre - 999.99 et 999.99 il faut indiquer (5,2). | REAL |
| REAL | Nombre décimal à virgule flottante | FLOAT |
| BOOLEAN | Valeur booléenne où 0 = Faux et 1 = Vrai. | INTEGER |
| BIT(M) | Chaine binaire. Les valeurs possibles sont 0 et 1. M équivaut au nombre de bits de la chaine. Si le M n'est pas spécifié, il a une valeur de 1. BIT ou BIT(1) peut être préférable au type BOOLEAN pour s'assurer d'une valeur booléenne. | Pas d'équivalent |
| CHAR(M) | Chaine de caractères de longueur fixe. M correspond à la longueur. M doit être entre 0 et 255. M = 0 => chaine vide ou NULL. | TEXT |
| VARCHAR(M) | Chaine de caractères de longueur variable. M correspond à la longueur maximale de la chaine. M doit être entre 0 et 65 532. M = 0 => chaine vide ou NULL. | TEXT |
| TEXT | Format à utiliser pour du texte libre. Ne permet pas l'indexation. | TEXT |
| JSON | Gère un contenu textuel sous forme JSON. | TEXT |
| BYTEA | Permet d'enregistrer des données en format binaire. | BLOB |
| DATE | Permet d'enregistrer une date sous le format yyyy-MM-dd | TEXT |
| TIME | Permet d'enregistrer une heure sous le format HH:mm:ss.ffffff | TEXT |
| TIMESTAMP | Permet d'enregistrer un moment précis d'une action de la base de données sous le format yyyy-MM-dd HH:mm:ss.ffffff L'utilisation est pour enregistrer un moment d'un événement précis lié à la base de données, comme le moment de la dernière modification de l'enregistrement. Le moment est entre 1970-01-01 00:00:01 et 2038-01-19 03:14:07. | TEXT |
| UUID | Identifiant universel unique. C'est très utile pour avoir un identifiant unique sans incrément 123e4567-e89b-12d3-a456-426614174000. | TEXT |
Pour avoir la liste complète : https://docs.postgresql.fr/16/datatype.html
Nomemclature avec PostgreSQL
PostgreSQL est différent des autres SGBD, car par défaut PostgreSQL met toutes les noms de tables, base de données, utilisateurs ou colonnes sont automatiquement mis en minuscule.
Cela fait que spécialement pour PostgreSQL, certains développeurs utilisent la nomenclature snake_case au lieu de PascalCase pour gérer les noms. Cela évite les conflits potentiels. C'est à vous de choisir ce que vous préférez comme nomenclature, mais l'important c'est d'être constant.
Voici un exemple :
CREATE TABLE Enseignants( EnseignantId INTEGER NOT NULL PRIMARY KEY, Prenom VARCHAR(25) NOT NULL, Nom VARCHAR(25) NOT NULL);
PostgreSQL va créer la table enseignants avec les colonnes enseignantid, prenom et nom. Cela est géré automatiquement. Donc, si l'on fait un SELECT :
SELECT *FROM EnseignantsWHERE Prenom Like '%Serge'
est l'équivalent de
SELECT *FROM enseignantsWHERE prenom Like '%Serge'
Cependant, il est possible de dire à PostgreSQL que je veux absolument le nom de la table avec la première lettre en majuscule. Il faut ajouter des doubles guillemets "".
CREATE TABLE "Enseignants"( "EnseignantId" INTEGER NOT NULL PRIMARY KEY, "Prenom" VARCHAR(25) NOT NULL, "Nom" VARCHAR(25) NOT NULL);
Il faut faire de même avec le SELECT :
SELECT *FROM "Enseignants"WHERE "Prenom" Like '%Serge'
Le problème est que la requête suivante ne marchera pas, car PostgreSQL ne transformera pas les valeurs en minuscule :
SELECT *FROM enseignantsWHERE prenom Like '%Serge'--Ça ne marche pas :( car PostgreSQL s'attend à "Enseignants"
C'est pour ces raisons que snake_case est plus courant avec PostgreSQL, même si ce n'est pas le standard par défaut de SQL.
L'objectif étant d'éviter les doubles guillemets "" partout!
CREATE TABLE enseignants( enseignant_id INTEGER NOT NULL PRIMARY KEY, prenom VARCHAR(25) NOT NULL, nom VARCHAR(25) NOT NULL);
Auto-incrémentation d'une clé - GENERATED ALWAYS AS IDENTITY
Pour générer une clé automatiquement dans une table, il faut spécifier le règle GENERATED ALWAYS AS IDENTITY sur le champ de la clé primaire numérique (SMALLINT, INT ou BIGINT).
Voici un exemple de création d'une table avec une règle d'auto-incrémentation.
CREATE TABLE enseignants( enseignant_id INTEGER NOT NULL PRIMARY KEY GENERATED ALWAYS AS IDENTITY, prenom VARCHAR(25) NOT NULL, nom VARCHAR(25) NOT NULL);
Il ne faut pas spécifier le champ de la clé lors de l'insertion pour utiliser la règle d'auto-incrémentation. L'auto-incrémentation débute à 1.
INSERT INTO enseignants(prenom, Nom) VALUES ('François', 'St-Hilaire'), --Le id sera 1 ('Stéphane', 'Janvier'), --Le id sera 2 ('Louis', 'Marchand'); --Le id sera 3
Si l'enregistrement de la clé #2 est supprimé, le prochain enregistrement aura la clé 4. L'auto-incrémentation continue sa séquence, sans revenir en arrière.
DELETE FROM enseignants WHERE enseignant_id = 2;INSERT INTO enseignants(prenom, nom) VALUES ('Frédéric', 'Montembeault'); --Le id sera 4
Auto-incrémentation d'une clé manuellement
Il est possible d'assigner manuellement une clé. Cependant, il faut changer GENERATED ALWAYS AS IDENTITY pour GENERATED BY DEFAULT AS IDENTITY. Car ALWAYS ne permet pas de mettre manuellement la clé.
CREATE TABLE enseignants2( enseignant_id INTEGER NOT NULL PRIMARY KEY GENERATED BY DEFAULT AS IDENTITY, prenom VARCHAR(25) NOT NULL, nom VARCHAR(25) NOT NULL);
Ensuite, il suffit de spécifier le champ dans l'insertion.
INSERT INTO enseignants2(enseignant_id, prenom, nom) VALUES (9, 'Benoit', 'Tremblay'); --Le id sera 9
Le prochain enregistrement de l'auto-incrément sera maintenant 10. Les clés 5 à 8 peuvent être utilisées uniquement avec une insertion manuelle. La valeur de l'auto-incrément se base à partir de la valeur la plus grande de la table.
INSERT INTO enseignants2(Prenom, Nom) VALUES ('Pierre-Luc', 'Boulanger'); --Le id sera 10INSERT INTO enseignants2(enseignant_id, prenom, nom) VALUES (6, 'Benoit', 'Desrosiers'); --Le id sera 6INSERT INTO enseignants2(prenom, nom) VALUES ('Nathalie', 'Cadrin'); --Le id sera 11
Pour plus d'information : https://www.postgresqltutorial.com/postgresql-tutorial/postgresql-identity-column/
Commentaires
Pour faire un commentaire, il faut utiliser deux tirets --.
--Ceci est un commentaire.INSERT INTO enseignants(prenom, nom) VALUES ('Felix', 'Primeau'); --Le id sera 12
Sinon vous pouvez faire un commentaire sur plusieurs lignes :
/* C'est un commentaire* Sur plusieurs lignes */INSERT INTO enseignants(prenom, nom) VALUES ('Felix', 'Primeau');
Champ TIMESTAMP
Il est fréquent dans les bases de données d'avoir un champ qui enregistre le moment de la dernière modification.
Le type utilisé pour ce champ est TIMESTAMP. Il est important d'indiquer une valeur par défaut pour laisser le SGBDR s'en occuper pour nous.
La constante CURRENT_TIMESTAMP consiste au moment actuel.
--Destruction de la table existanteDROP TABLE IF EXISTS enseignants;CREATE TABLE IF NOT EXISTS enseignants( enseignant_id INTEGER NOT NULL PRIMARY KEY GENERATED BY DEFAULT AS IDENTITY, prenom VARCHAR(30) NOT NULL CHECK(prenom <> ''), nom VARCHAR(30) NOT NULL CHECK(nom <> ''), creation TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP);
Lors de l'insertion d'une valeur, il est important de ne pas déclarer le champ creation pour que le système utilise la valeur par défaut.
Le champ creation a une date qui correspond au moment de l'exécution de la commande INSERT.
--enseignant_id n'est pas spécifié pour laisser le SGBD s'en occuperINSERT INTO enseignants(Prenom, Nom) VALUES ('François', 'St-Hilaire');
La version actuelle de PostgreSQL permet d'avoir plusieurs champs de type TIMESTAMP dans la même table. Il est donc possible de créer un champ pour enregistrer la date de création et un champ pour la dernière modification.
Malheureusement, si on veut faire la même chose avec une colonne modification, ce n'est pas possible de mettre à jour la valeur automatiquement à chaque mise à jour sans utiliser ce que l'on appelle un trigger. Un trigger est une fonction qu'on exécute selon un déclencheur. C'est un concept plus avancé. Il faut le gérer manuellement dans ce cas.
--Destruction de la table existanteDROP TABLE IF EXISTS enseignants;--Création de la nouvelle définition de la tableCREATE TABLE IF NOT EXISTS enseignants( enseignant_id INTEGER NOT NULL PRIMARY KEY GENERATED BY DEFAULT AS IDENTITY, prenom VARCHAR(30) NOT NULL CHECK(prenom <> ''), nom VARCHAR(30) NOT NULL CHECK(Nom <> ''), creation TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, modification TIMESTAMP NULL);INSERT INTO enseignants(enseignant_id, prenom, nom) VALUES (1, 'François', 'St-Hilaire');--Lors de l'insertion, le champ modification est toujours NULLUPDATE enseignants SET prenom = 'Frank' WHERE enseignant_id = 1;--Lors de la mise à jour, le champ modification est toujours NULL et le champ creation reste inchangé.UPDATE enseignants SET prenom = 'Franky', modification = CURRENT_TIMESTAMPWHERE enseignant_id = 1;--Lors de la 2e mise à jour, le champ modification a une nouvelle valeur et le champ creation reste inchangé.
Pour votre curiosité, voici à quoi ressemblerait le trigger pour mettre à jour automatiquement la colonne modification :
CREATE TRIGGER update_enseignants_time BEFORE UPDATE ON enseignants FOR EACH ROW EXECUTE PROCEDURE update_modification_column();
Le trigger s'applique sur chaque UPDATE sur la table enseignants et va appeler update_modification_column
CREATE OR REPLACE FUNCTION update_modification_column() RETURNS TRIGGER AS $$BEGIN NEW.modification = CURRENT_TIMESTAMP; RETURN NEW; END;$$ language 'plpgsql';
La fonction update_modification_column applique la modification pour chaque valeur en assignant CURRENT_TIMESTAMP à modification.
Maintenant, si vous testez cette requête sans la mise à jour de modification :
UPDATE enseignants SET prenom = 'Franky'WHERE enseignant_id = 1;
Vous devriez voir une valeur à jour dans le champs modification
Changement de base de données
Un SGBDR a généralement plusieurs bases de données. Pour s'assurer qu'un script utilise la bonne base de données, il est important de choisir la bonne base de données.
Généralement avec PostgreSQL et pgAdmin, le contexte dans lequel on ouvre notre requête est important.
Pour cela, vous devez faire un clique droit sur la base de données que vous désirez travailler :
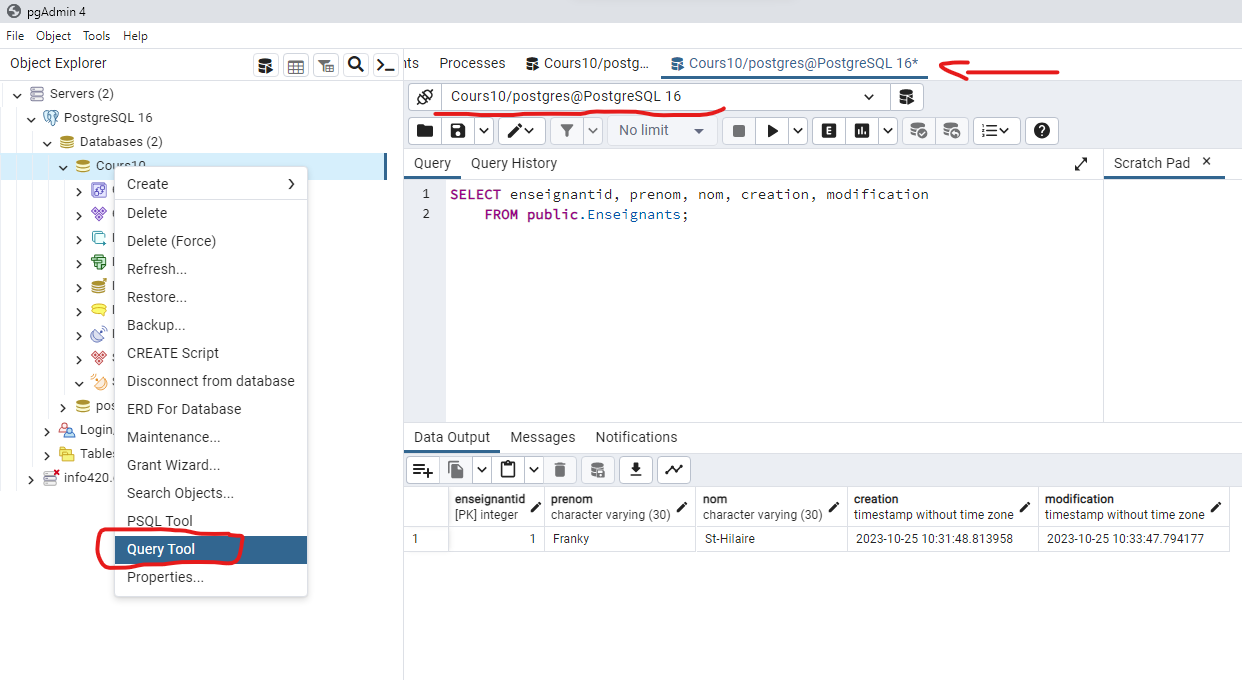
Sélectionnez Query Tool pour ouvrir une fenêtre de requête. Vous allez toujours voir le nom de la connexion dans le menu déroulant plus haut. Dans notre cas c'est Cours10/postgres@PostrgreSQL 16. La première partie est le nom de la base de données Cours10. La deuxième partie est le nom de l'utilisateur connecté postgres et la dernière partie est le nom du serveur : PostrgreSQL 16. À partir de cela, on peut faire des requêtes sur n'importe quelle schéma de la base de données Cours10. Par défaut, le schéma s'appelle public, mais il est possible de créer d'autres schémas.
C'est pourquoi il y a parfois public. avant le nom de la table enseignants. Cela permet de préciser le schéma :
SELECT *FROM public.enseignants;
Création d'une base de données - CREATE DATABASE
Jusqu'à maintenant, nous avons vu la création d'une base de données par pgAdmin, mais lors d'un script de création, il est préférable de le faire par code.
La commande CREATE DATABASE permet de créer une base de données.
CREATE DATABASE exemple1;
Allez dans pgAdmin pour voir la liste des bases de données. Le jeu de donnée de la base de données exemple1 sera UTF8. Si le jeu de données n'est pas spécifié, la base de données utilisera celle par défaut dans le SGBDR.
Il est préférable de la spécifier lors de la création. Dans le cadre de ce cours, le jeu de caractères sera UTF8.
CREATE DATABASE exemple1 WITH ENCODING = 'UTF8' LC_COLLATE = 'French_Canada.1252' LC_CTYPE = 'French_Canada.1252';
Vous pouvez spécifier l'utilisateur propriété de la base de données avec OWNER = MonUtilisateur
CREATE DATABASE exemple1 WITH OWNER = boulangerp ENCODING = 'UTF8' LC_COLLATE = 'French_Canada.1252' LC_CTYPE = 'French_Canada.1252';
Pour plus d'information : https://www.postgresql.org/docs/current/sql-createdatabase.html
Destruction d'une base de données - DROP DATABASE
Il est possible de détruire une base de données par code également.
La commande est DROP DATABASE et ensuite il faut spécifier le nom.
DROP DATABASE exemple1;
Il est possible d'utiliser la vérification IF EXISTS pour éviter des erreurs d'exécution si aucune base de données avec ce nom existe.
DROP DATABASE IF EXISTS exemple1;
Attention : Une destruction d'une base de données détruit tous les éléments de la base de données (Tables, Procédures, Vues...) et les données. Il n'y a pas de retour en arrière possible sans sauvegarde.
Accès utilisateur
Créer un utilisateur - CREATE USER
Dans le dernier cours, l'utilisateur postgres a été créé. Cet utilisateur a tous les privilèges du SGBDR, c'est-à-dire qu'il est administrateur du SGBDR et des bases de données du serveur.
Lorsqu'une application utilise une base de données, il est préférable que l'application possède son propre utilisateur et que ses accès soient limités. Il est préférable que l'utilisateur puisse accéder uniquement à la base de données de l'application et que ses privilèges se limitent uniquement au CRUD (CREATE READ UPDATE DELETE).
À noter qu'un utilisateur permet d'accéder au serveur en tant que tel et de voir toutes les bases de données du serveur si l'on ne change pas ces droits.
Pour être en mesure de créer un utilisateur, il faut être administrateur du SGBDR ou avoir le rôle CREATEROLE.
CREATE USER utilisateur WITH PASSWORD 'motdepasse';
Il faut remplacer utilisateur par le nom de l'utilisateur et motdepasse par le mot de passe.
Pour créer l'utilisateur prof avec le mot de passe 3N3!database.
CREATE USER prof WITH PASSWORD '3N3!database';
On peut préciser à la création de l'utilisateur des autorisations avec WITH suivi de :
- S'il peut se connecter ou non (
LOGINouNOLOGIN) - S'il peut créer d'autres rôles/utilisateurs (
CREATEROLEouNOCREATEROLE) - S'il peut créer des bases de données (
CREATEDBouNOCREATEDB) - S'il est un super utilisateur (
SUPERUSERouNOSUPERUSER)
Par défaut, les valeurs sont à NO** par défaut sauf pour le LOGIN qui est automatiquement attribué.
Par exemple, si on veut créer un utilisateur qui a le droit de créer d'autres utilisateurs et de créer des bases de données :
CREATE USER megaProf WITH CREATEROLE CREATEDB PASSWORD '3N3!database';
Notre utilisateur a accès au serveur et à toutes les bases de données par défaut avec le schéma public, mais ne peut pas voir les tables et exécuter des opérations sur celles-ci.
Pour cela, il faut spécifier les droits pour cet utilisateur pour une base de données. Les droits seront uniquement pour le CRUD.
Voici l'exemple pour l'utilisateur prof si on exécute le script à l'intérieur d'une base de données pour toutes les tables à l'intérieur du schéma public.
GRANT SELECT, INSERT, UPDATE, DELETE ON ALL TABLES IN SCHEMA public TO prof;
À partir de pgAdmin, créez une nouvelle connexion et utilisez le compte prof. Il aura accès à toutes les bases de données, mais il ne sera pas en mesure de voir les tables de toutes les BDs sauf celle qu'on a exécuté l'assignation. L'utilisateur devrait pouvoir lire et modifier des données, mais pas de créer des tables CREATE TABLE dans cette base de données. Il pourra seulement faire les commandes suivantes : SELECT, INSERT, UPDATE, DELETE.
modification d'un mot de passe
Le mot de passe est en clair dans le script. Ce qui n'est pas très sécuritaire si le script est enregistré sur le disque. Il est recommandé que l'utilisateur modifie son mot de passe après sa première connexion.
ALTER USER prof WITH PASSWORD 'MonPassPerso!!!!';
Le mot de passe devra être mis à jour dans les connexions.
Détruire un utilisateur
Pour supprimer un utilisateur, la commande est DROP USER. Il faut être administrateur pour être en mesure de le faire.
DROP USER prof
Utilisateur root avec PostgreSQL
Attention : Lors de l'installation de PostgreSQL, l'utilisateur admin est également créé. Cet utilisateur est le véritable administrateur du SGBDR. Donc, si vous faites une installation sur un serveur de compagnie ou partagé pour de la production, il faut mettre un mot de passe complexe. Il est important de ne pas partagé à n'importe qui ce mot de passe.
Création d'une base de données
Voici un exemple de la base de données gestion_films.
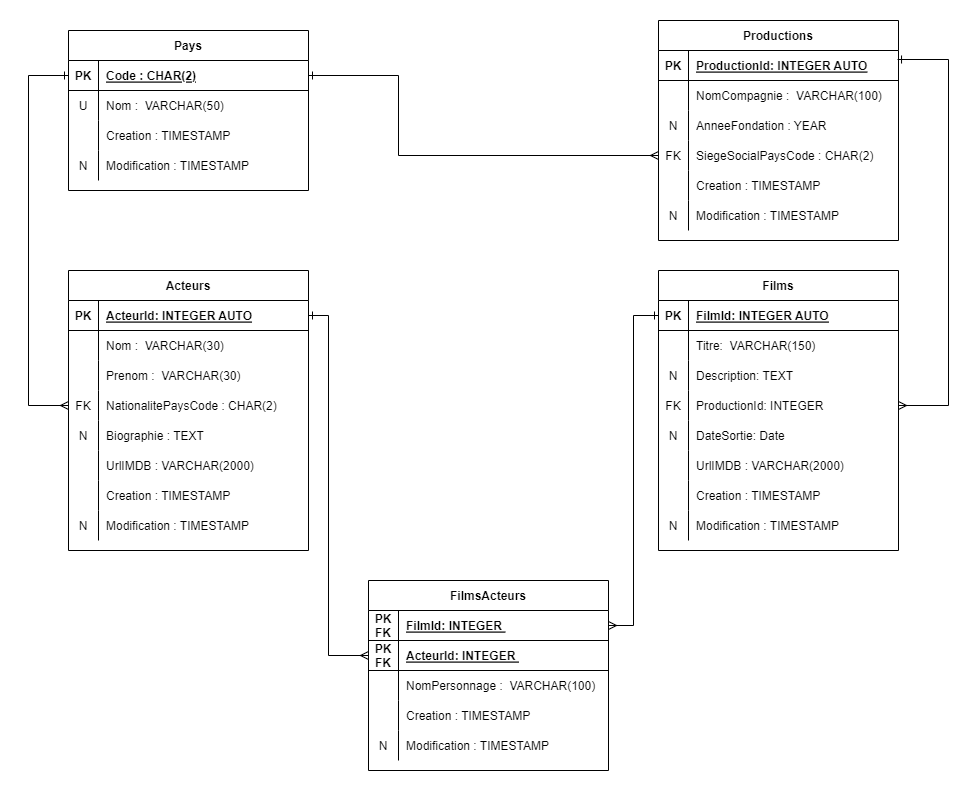
Voici le script en deux parties :
CREATE DATABASE gestion_films WITH ENCODING = 'UTF8' LC_COLLATE = 'French_Canada.1252' LC_CTYPE = 'French_Canada.1252';
CREATE TABLE IF NOT EXISTS pays( code CHAR(2) NOT NULL PRIMARY KEY, nom VARCHAR(50) NOT NULL UNIQUE CHECK(nom <> ''), creation TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, modification TIMESTAMP NULL);CREATE TABLE IF NOT EXISTS acteurs( acteur_id INTEGER NOT NULL PRIMARY KEY GENERATED BY DEFAULT AS IDENTITY, nom VARCHAR(30) NOT NULL CHECK(nom <> ''), prenom VARCHAR(30) NOT NULL CHECK(prenom <> ''), nationalite_pays_code CHAR(2) NOT NULL, biographie TEXT, url_IMDB VARCHAR(2000) NOT NULL CHECK(url_IMDB LIKE 'https://%'), creation TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, modification TIMESTAMP NULL, FOREIGN KEY(nationalite_pays_code) REFERENCES pays(Code) ON DELETE RESTRICT ON UPDATE CASCADE);CREATE TABLE IF NOT EXISTS productions( production_id INTEGER NOT NULL PRIMARY KEY GENERATED BY DEFAULT AS IDENTITY, nom_compagnie VARCHAR(100) NOT NULL CHECK(nom_compagnie <> ''), annee_fondation INTEGER NOT NULL CHECK(annee_fondation >= 1900), siege_social_pays_code CHAR(2) NOT NULL, creation TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, modification TIMESTAMP NULL, FOREIGN KEY(siege_social_pays_code) REFERENCES pays(Code) ON DELETE RESTRICT ON UPDATE CASCADE);CREATE TABLE IF NOT EXISTS films( film_id INTEGER NOT NULL PRIMARY KEY GENERATED BY DEFAULT AS IDENTITY, titre VARCHAR(150) NOT NULL CHECK(titre <> ''), description TEXT DEFAULT 'Description non disponible', production_id INTEGER NOT NULL, date_sortie DATE, url_IMDB VARCHAR(2000) NOT NULL CHECK(url_IMDB LIKE 'https://%'), creation TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, modification TIMESTAMP NULL, FOREIGN KEY (production_id) REFERENCES productions(production_id) ON DELETE RESTRICT ON UPDATE CASCADE);CREATE TABLE IF NOT EXISTS films_acteurs( film_id INTEGER NOT NULL, acteur_id INTEGER NOT NULL, nom_personnage VARCHAR(100) NOT NULL CHECK(nom_personnage <> ''), creation TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, modification TIMESTAMP NULL, PRIMARY KEY (film_id, acteur_id), FOREIGN KEY(film_id) REFERENCES films(film_id) ON DELETE RESTRICT ON UPDATE CASCADE, FOREIGN KEY(acteur_id) REFERENCES acteurs(acteur_id) ON DELETE RESTRICT ON UPDATE CASCADE);
Cependant avec pgAdmin, il n'est pas possible d'exécuter la création de la base de données en même temps que la création de table. Il faut séparer cela en deux exécutions.
Cependant, il est possible de faire la création en une commande avec la ligne de commande psql. Il suffit d'ajouter \c NomBD; entre le CREATE DATABASE et la première création de la table. Exemple :
CREATE DATABASE gestion_films WITH ENCODING = 'UTF8' LC_COLLATE = 'French_Canada.1252' LC_CTYPE = 'French_Canada.1252';\c Gestionfilms;--Création des tables
Vous pouvez exécuter le script avec la commande suivante -> psql -U postgres -a -f monscript.sql
Concaténation - CONCAT()
Avec PostgreSQL, la concaténation de chaîne de caractères doit se faire avec la fonction CONCAT().
Par exemple, pour concaténer le prénom et le nom de l'acteur sous la colonne nom_complet, il faut faire la requête ci-dessous.
SELECT CONCAT(prenom, ' ', nom) AS nom_completFROM acteurs;
Exercice
Version originale par François St-Hilaire
Mise à jour 2023 par Pierre-Luc Boulanger