Sécurité et confidentialité des données
La sécurité des données confidentielles est très importante dans les systèmes informatiques.
Dans les logiciels, il faut appliquer le principe "Ai-je besoin de savoir ?". Ce principe consiste à se demander si l'utilisateur a besoin de savoir l'information qui est affichée à l'écran. Si la réponse est non, il faut lui empêcher l'accès à la voir.
Il est possible de ne pas lui permettre de la voir par la gestion de la sécurité interne de l'application. Mais est-ce que la donnée est bien confidentielle dans la base de données ?
Il faut se demander si une personne est en mesure d'avoir accès directement à la base de données, est-ce dangereux qu'il ait accès à l'information ? Si la réponse est oui, il faut penser à une mécanique de cryptage des données.
Par exemple, il ne faut pas que l'équipe de marketing ait accès aux ventes des clients. Mais est-ce que l'information des ventes doit être confidentielle si j'ai un accès directement à la base de données ? Pas vraiment, ce n'est pas une donnée sensible.
Par contre, est-ce que le numéro d'assurance sociale d'une personne doit être confidentiel si j'ai un accès direct à la base de données ? Il serait préférable que cette donnée ne soit pas enregistrée sans cryptage dans la base de données. Même chose pour le mot de passe d'un utilisateur. Il ne doit pas être visible.
Module pgcrypto
Pour utiliser des fonctions de cryptage et décryptage, il faut installer un module (ou EXTENSION) qui s'appelle pgcrypto.
Exécuter cette ligne dans une requête pour la base de données que vous voulez faire de l'encryption.
CREATE EXTENSION IF NOT EXISTS pgcrypto;
Le module est automatiquement installé pour toute la base de données. Donc, à la création des tables, c'est une bonne idée d'ajouter le module pour ne pas l'oublier!
Cryptage réversible - pgp_sym_encrypt() et pgp_sym_decrypt()
Le cryptage réversible est utilisé pour les données qui doivent être affichées de nouveau en texte clair ou lisible à l'utilisateur.
Par exemple, le numéro d'assurance sociale doit être récupéré pour produire les formulaires d'impôt.
Pour être en mesure de crypter une donnée en mode réversible, il faut utiliser en algorithme de cryptage reconnu et une clé privée. La sécurité du message réside dans la capacité de conserver la clé privée sécuritairement. Si tout le monde connait la clé, le message n'est plus très sécuritaire.
Avec PostgreSQL, l'algorithme qui sera utilisé sera AES. Cette méthode permet de convertir une chaine de caractères en une série d'octets.
La méthode pour le cryptage est pgp_sym_encrypt('Message clair', 'Clé') et pour le décryptage est pgp_sym_decrypt(Message crypte, 'Clé')
Le numéro d'assurance sociale (nas) est un bon candidat pour le cryptage réversible.
La table ci-dessous est utilisée pour enregistrer le nas en texte clair.
CREATE TABLE employes( employe_id INTEGER NOT NULL PRIMARY KEY GENERATED BY DEFAULT AS IDENTITY, prenom VARCHAR(50) NOT NULL, nom VARCHAR(50) NOT NULL, nas CHAR(9) NOT NULL);INSERT INTO employes(prenom, nom, nas) VALUES ('François', 'St-Hilaire', '000111222');
Pour être en mesure de faire le cryptage, il faut convertir le champ nas en type BYTEA.
CREATE TABLE employes( employe_id INTEGER NOT NULL PRIMARY KEY GENERATED BY DEFAULT AS IDENTITY, prenom VARCHAR(50) NOT NULL, nom VARCHAR(50) NOT NULL, nas BYTEA NOT NULL);
Il faut utiliser la méthode pgp_sym_encrypt() dans l'insertion.
INSERT INTO employes(prenom, nom, nas) VALUES ('François', 'St-Hilaire', pgp_sym_encrypt('012325985', 'Ma clé confidentielle!!!'));
Pour voir l'information dans la base de données, il faut exécuter la requête ci-dessous.
SELECT employe_id, prenom, nom, nas FROM employes;--Le résultatemploye_id prenom nom nas1 Francois St-Hilaire [binary data]
Le nas est une représentation des octets cryptés du message. C'est en réalité un tableau d'octets ou byte[] en type de programmation. Par défaut PostgreSQL ne montre pas ces valeurs explicitement. De toute façon, ce ne serait pas lisible 😉.
Pour être en mesure de voir le nas, il faut mettre la méthode de décryptage dans les champs du SELECT.
SELECT prenom, nom, pgp_sym_decrypt(nas, 'Ma clé confidentielle!!!') AS NASClairFROM employes;--Le résultatemploye_id prenom nom NASClair1 Francois St-Hilaire 012325985
Si vous faites une erreur avec la clé, la méthode lancera une exception Wrong Key or corrupt data.
Pour faciliter le transport des données cryptées, l'utilisation du Base64 est intéressante. L'encodage en Base64 permet de transformer une série d'octets en une représentation en chaine de caractères. L'utilisation du Base64 n'est pas une méthode de cryptage, c'est une méthode de conversion de l'affichage.
Dans le cas du Base64, il faut que le champ soit une chaine de caractères. TEXT est le type qui permet de gérer ces longues chaînes de caractères. Il faut utiliser la méthode armor() et dearmor() pour transformer les octets en texte.
CREATE TABLE employes( employe_id INTEGER NOT NULL PRIMARY KEY GENERATED BY DEFAULT AS IDENTITY, prenom VARCHAR(50) NOT NULL, nom VARCHAR(50) NOT NULL, nas TEXT NOT NULL);--InsertionINSERT INTO employes(prenom, nom, nas) VALUES ('Francois', 'St-Hilaire', armor(pgp_sym_encrypt('012325985', 'Ma clé confidentielle!!!')));--SelectionSELECT prenom, nom, pgp_sym_decrypt(dearmor(nas), 'Ma clé confidentielle!!!') AS NASClairFROM employes;--Le résultatemploye_id prenom nom NASClair1 Francois St-Hilaire 012325985
Cryptage non réversible ou hachage - digest()
Le cryptage non réservible ou hachage (hash) est une méthode qui transforme un message et qui retourne un résultat. Il n'est pas possible de prendre le résultat et de faire l'opération inverse pour connaitre le message d'origine. Au sens strict, ce n'est pas réellement du cryptage, mais du hachage.
Le mode de hachage utilisé doit s'assurer qu'il ne génère pas de collisions. Une collision est que 2 messages différents peut générer la même réponse identique. La méthode de hachage recommandée pour PostgreSQL est le SHA2 avec 512 bits (sha512). La méthode SHA2 avec 512 bits retourne une chaine d'octets qui contient en réalité 128 caractères. Les méthodes de hachage MD5 et SHA1 ne sont plus considérées sécuritaires.
Le cryptage non réversible est utilisé pour les mots de passe principalement. Les personnes utilisent souvent les mêmes mots de passe entre plusieurs systèmes, il est donc important que si la base de données est compromise, qu'il ne soit pas possible de connaitre le mot de passe.
CREATE TABLE employes( employe_id INTEGER NOT NULL PRIMARY KEY GENERATED BY DEFAULT AS IDENTITY, prenom VARCHAR(50) NOT NULL, nom VARCHAR(50) NOT NULL, utilisateur VARCHAR(50) NOT NULL, mot_de_passe BYTEA NOT NULL);--Le mot de passe est password12INSERT INTO employes(prenom, nom, utilisateur, mot_de_passe) VALUES ('Francois', 'St-Hilaire', 'fsthilaire', digest('password12', 'sha512'));SELECT * FROM employes;
| employe_id | prenom | nom | utilisateur | mot_de_passe |
|---|---|---|---|---|
| 1 | Francois | St-Hilaire | fsthilaire | binary data |
Si on veut voir la valeur hexadécimal, il faut utiliser encode -> encode(mot_de_passe, 'hex').
Dans notre cas, la valeur serait 552dc2e616c351e1a6ffaadb32dbacbaaeeb8359a9f6ec33668e9265997c8aa8fa8b501c6759b989742bf0b4e566ecf2079f9359d3224ecef116ce42c4ec07ad
Pour déterminer si l'utilisateur a le bon mot de passe, il faudra effectuer une requête et hacher le mot de passe envoyé par l'utilisateur.
--FonctionneSELECT * FROM employesWHERE utilisateur = 'fsthilaire' AND mot_de_passe = digest('password12', 'sha512');--Ne fonctionne pas, car ne retourne rienSELECT * FROM employesWHERE utilisateur = 'fsthilaire' AND mot_de_passe = digest('GrosMDP!!!', 'sha512');
Si la requête retourne un enregistrement, l'utilisateur a accès. Si aucun enregistrement n'est retourné, la combinaison utilisateur/mot de passe n'est pas valide.
Cryptage ou hachage prévisible - Salage
En cryptographie, il est important que le cryptage ne soit pas prévisible, c'est-à-dire que pour un message identique, il ne doit pas avoir le même résultat pour le message crypté. Cette notion n'est pas nécessaire pour le TP3, mais elle est importante dans une utilisation réelle.
Prenez par exemple la table ci-dessous et les insertions. Les 2 insertions ont la même valeur pour le mot de passe et pour le nas.
CREATE TABLE employes( employe_id INTEGER NOT NULL PRIMARY KEY GENERATED BY DEFAULT AS IDENTITY, prenom VARCHAR(50) NOT NULL, nom VARCHAR(50) NOT NULL, nas BYTEA NOT NULL, utilisateur VARCHAR(50) NOT NULL, mot_de_passe BYTEA NOT NULL);INSERT INTO employes(prenom, nom, nas, utilisateur, mot_de_passe) VALUES ('Francois', 'St-Hilaire', pgp_sym_encrypt('012325985', 'Ma clé confidentielle!!!'), 'fsthilaire', digest('password12', 'sha512')), ('Stéphane', 'Janvier', pgp_sym_encrypt('012325985', 'Ma clé confidentielle!!!'), 'sjanvier', digest('password12', 'sha512'));
| employe_id | prenom | nom | utilisateur | mot_de_passe |
|---|---|---|---|---|
| 1 | Francois | St-Hilaire | fsthilaire | 552dc2e616c351e1a6ffaadb32dbacbaaeeb8359a9f6ec33668e9265997c8aa8 fa8b501c6759b989742bf0b4e566ecf2079f9359d3224ecef116ce42c4ec07ad |
| 2 | Stéphane | Janvier | sjanvier | 552dc2e616c351e1a6ffaadb32dbacbaaeeb8359a9f6ec33668e9265997c8aa8 fa8b501c6759b989742bf0b4e566ecf2079f9359d3224ecef116ce42c4ec07ad |
En regardant ces résultats, un utilisateur mal intentionné peut savoir que les 2 personnes ont exactement la même valeur pour les 2 champs. Ceci donne un indice considérable.
Pour le cryptage AES, il peut être difficile de déterminer le message d'origine, malgré qu'il est identique dans les 2 cas. Par contre, pour le hachage, il existe des rainbow table qui ont une liste de nombreux hachage des mots de passe les plus populaires. Il est donc possible de retrouver le message.
Voici un site qui contient une rainbow table pour du SHA2 avec 512 bits : https://crackstation.net/
Essayez de trouver la réponse pour le hash de password12 : 552dc2e616c351e1a6ffaadb32dbacbaaeeb8359a9f6ec33668e9265997c8aa8fa8b501c6759b989742bf0b4e566ecf2079f9359d3224ecef116ce42c4ec07ad.
Le site l'a malheureusement trouvé. Donc il est possible de savoir que les 2 utilisateurs ont le mot de passe password12.
Essayez de trouver le mot de passe avec ces hachages.
472130cb3c290c6386d086780fa1660dd98a5452dddde34c520434bdee2229513e6b840281b7f4469a78d71fcfd5cf65e10915b41954aa011d2ac48f6f1062a7 81378c52a6ea72d3928d875b788b2eb792eadab021091b78fd11741a09f1abc4924622454c8816e26f825b8e685006466d7ba086db3b8ba6fcf4f74bbe0ac1b3 2904a377dbc3a76d37c6d634eb4c37f68aff796e22fe37f7987d59fba5a01b302bf66840f621e1a8dff3d30585b0e50bbeaef4f3e00a31b6f24af4d924dd088c
Les 2 premiers sont dans la table, mais pas le 3e.
L'une des techniques qui permettent d'éviter d'avoir du hachage non prévisible est d'utiliser la technique du salage. Le salage ou salt consiste à ajouter au début ou à la fin du message une chaîne aléatoire. Le salt est une donnée publique, car il faut la connaître pour essayer de faire la comparaison.
UPDATE employesSET mot_de_passe = digest(CONCAT('mon sel à ajouter','password12'), 'sha512')WHERE employe_id = 1;UPDATE employesSET mot_de_passe = digest(CONCAT('mon sel à ajouter','password12'), 'sha512')WHERE employe_id = 2;--Résultat avec le salt757ac82a21b3a949ec2fe16083cc4a15decaa250c174ac4803a9cb16ff90fdd688fd17608f1951b7d9b4d74d4b0a13e908735d62351799ec631bae5427d90f07
Il est important que le salage soit différent pour chacun des messages, car il existe plusieurs mots de passe classiques. Les mots de passe identiques seront protégés des rainbow table, mais pas par l'analyse statistique. En effectuant dans la base de données un GROUP BY sur le mot de passe, il sera possible de trouver le hachage le plus populaire. Il est ensuite possible d'essayer les mots de passe les plus populaires par force brute et espérer réussir.
Il existe plusieurs techniques d'enregistrer le salt avec le mot de passe. Le plus simple est d'avoir un champ à part.
CREATE TABLE employes( employe_id INTEGER NOT NULL PRIMARY KEY GENERATED BY DEFAULT AS IDENTITY, prenom VARCHAR(50) NOT NULL, nom VARCHAR(50) NOT NULL, utilisateur VARCHAR(50) NOT NULL, mot_de_passe BYTEA NOT NULL, salt VARCHAR(128));INSERT INTO employes(prenom, nom, utilisateur, mot_de_passe, salt)VALUES ('Francois', 'St-Hilaire', 'fsthilaire', digest(Concat('Mon sel','password12'), 'sha512'), 'Mon sel'), ('Stéphane', 'Janvier', 'sjanvier', digest(Concat('Ton sel','password12'), 'sha512'), 'Ton sel'); SELECT utilisateur, encode(mot_de_passe, 'hex'), saltFROM employes;
| utilisateur | mot_de_passe | salt |
|---|---|---|
| fsthilaire | 267118ff69bd8887220de553d3175ad8cbe89dc3ba05dede4555cdd2277da098 c64fe22514cfe0d6856834698a46b0fa62d4313b0dd93b8b0def7dcf77be2dd4 | Mon sel |
| sjanvier | aecef861af9546c6d80c192fc2c8b1a9d466952ce3796d2400d0c34f75c30912 563f00f32504e4663705f554f6c39d5c039dfea38b1b23f851515a05064abb6a | Ton sel |
Les 2 utilisateurs ont le même mot de passe, mais il est impossible de le savoir, car le salage est différent. Généralement, le salage est généré aléatoirement. Dans les logiciels, il existe plusieurs librairies qui s'occupent de la génération du salt et du hachage du mot de passe. La base de données gère uniquement la sauvegarde du hachage et non de le générer.
Pour faire la vérification, il faut comparer en ajoutant le salt au mot de passe.
SELECT *FROM employesWHERE utilisateur = 'fsthilaire' AND mot_de_passe = digest(concat(salt, 'password12'), 'sha512');
Sauvegarde et restauration des données
Pour les SGBD, il existe 2 niveaux de sauvegarde.
- Physique
Ce type de sauvegarde enregistre une copie des fichiers que le SGBD utilise pour le fonctionnement des bases de données. - Logique
Ce type de sauvegarde consiste à générer les scripts pour recréer le schéma de base de données et les données.
Dans ce cours, nous verrons uniquement la sauvegarde logique.
pg_dump - Sauvegarde logique
pg_dump est un utilitaire qui permet de générer le script de création de la base de données ainsi que les données.
L'utilitaire se retrouve dans le dossier C:\Program Files\PostgreSQL\16\bin\pg_dump.exe.
L'utilitaire a plusieurs options pour la génération du script. Pour plus d'information sur les options : https://www.postgresql.org/docs/current/app-pgdump.html
Le paramètre --username= est pour le nom de l'utilisateur.
Le paramètre --dbname est pour les bases de données.
Voici un exemple pour générer le script pour la base de données demo_c12.
pg_dump --username=gestion_bd --dbname=demo_c12 > C:\backup\demo_c12.sql
L'utilitaire va demander le mot de passe juste après. Il suffit de l'entrer. (ex: Mot de passe : bd3N3_1234!)
Remarquez que l'enregistrement du fichier se fait avec un redirecteur de sortie. Si le redirecteur n'est pas spécifié, le script sera affiché uniquement à l'écran.
C'est pratique d'avoir un fichier SQL si la base de données est petite. Cependant, si la base de données est plus grosses, l'utilisation d'un format archivé est plus pertinent.
Il suffit d'ajouter le paramètre custom à la requête et changer l'extension pour .backup au lieu de .sql
pg_dump --username=gestion_bd --dbname=demo_c12 --format=custom > C:\backup\demo_c12.backup
PostgreSQL - Restauration logique
Pour restorer la base de données, si on a un fichier SQL, on peut exécuter le fichier avec la commande psql dans une base de données vierge :
psql --username=gestion_bd -d demo_c12_v2 -f C:\backup\demo_c12.sql
Ou en exécutant le script sql directement dans pgAdmin. C'est important d'avoir créer la base de données au préalable!
Cependant, si l'on a utilisé le format custom (.backup), il faut utiliser l'utilitaire pg_restore
L'utilitaire se retrouve dans le dossier C:\Program Files\PostgreSQL\16\bin\pg_restore.exe.
pg_restore --username=gestion_bd -d postgres -f C:\backup\demo_c12.backup
Si la base de données existe déjà, il est possible de la recréer avec les options clean et create
pg_restore --username=gestion_bd --clean --create -d postgres -f C:\backup\demo_c12.backup
L'option -d est importante pour utiliser une base de données par défaut autre que demo_c12 pour recréer justement la base de données demo_c12
Sauvegarde et Restauration avec pgAdmin
Il est possible de faire la même chose, mais avec pgAdmin.
Avant il faut vérifier que pgAdmin connaît le chemin vers les exécutables de PostgreSQL, vous devez ouvrir le menu fichier et sélectionnez Préférences :
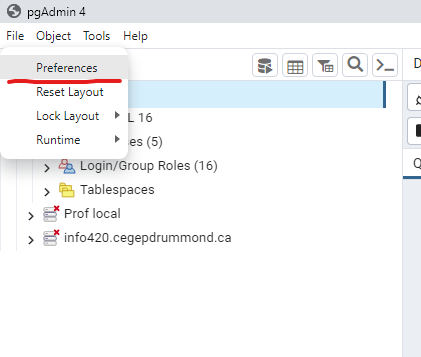
Dans la section Chemin des binaires, vous devez mettre à jour le chemin pour PostgreSQL 16 :
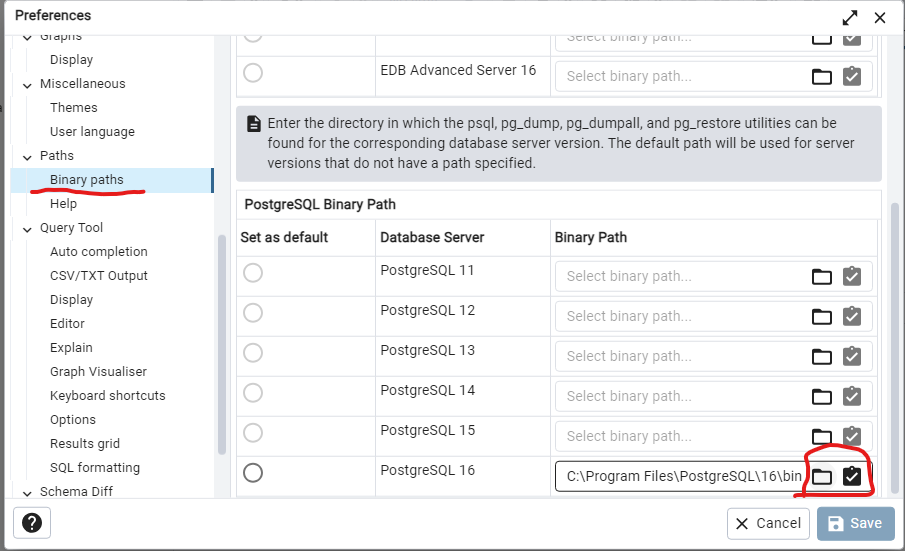
Sélectionnez le chemin similaire à C:\Program Files\PostgreSQL\16\bin. Pour vérifier, le chemin devrait contenir les exécutables de pg_restore et pg_dump.
Pour faire la sauvegarde d'une base de données. Sélectionnez la base de données avec un clique droit et choisissez Backup :

Vous devez faire le choix du format sql (Plain) ou custom (Dump) et sélectionnez l'endroit du fichier de sauvegarde. Les autres options ne sont pas obligatoires :
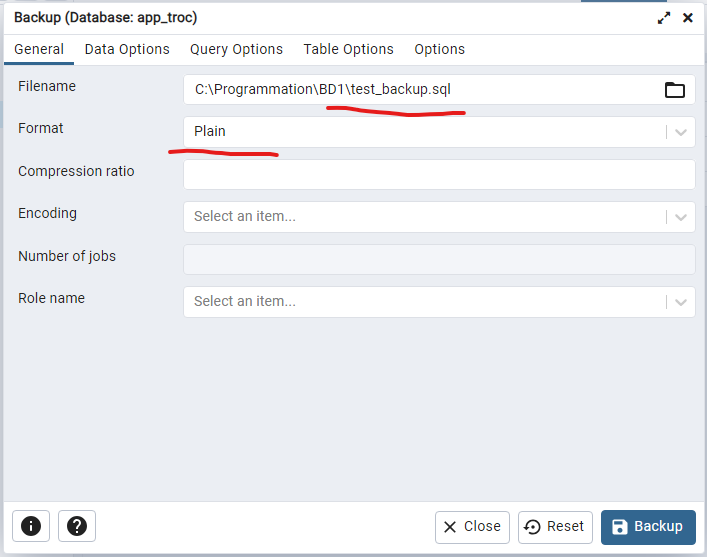
Similaire à la commande pg_dump tout dépend de la grosseur de votre base de données, mais généralement le format custom est compressé, donc plus intéressant.
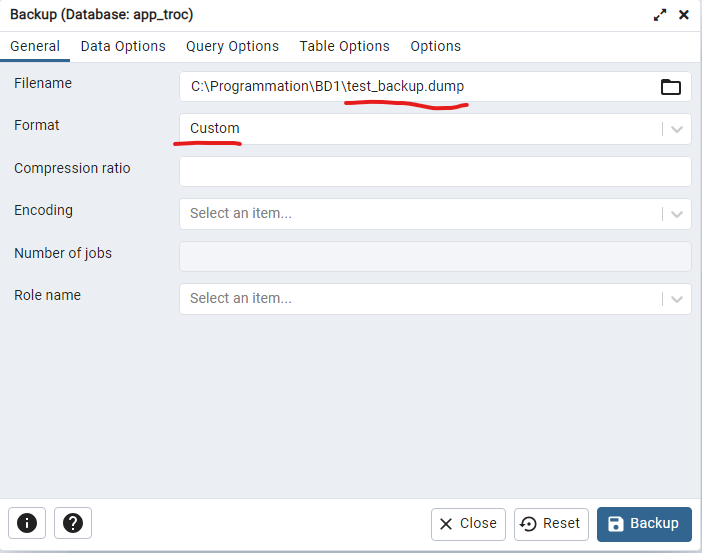
La dernière étape est de faire une restauration. Si vous avez choisie l'option sql ou Plain, vous pouvez l'exécuter directement dans une fenêtre de requête.
Sinon, similaire à la sauvegarde, il faut sélectionner la base de données avec un clique droit sur Restore. Si la base de données n'existe pas, vous pouvez la créer vide avant.
Dans le menu, choisissez le fichier de sauvegarde :

Si la base de données a déjà des données et des tables, il faut activer les options Clean et Create dans la section Query Options :
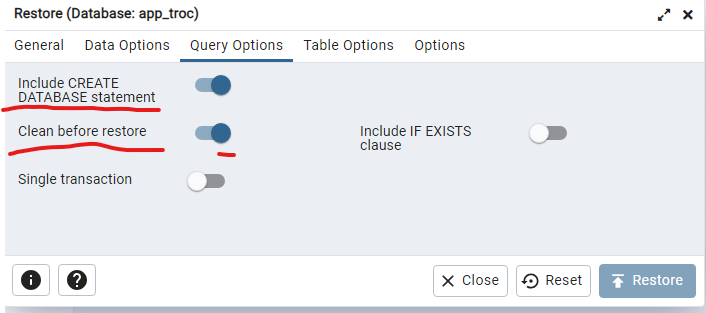
Fonction des dates
Il existe plusieurs fonctions qui permettent de manipuler les dates avec PostgreSQL.
Dans cette section, quelques-unes seront présentées.
Le format utilisé pour la date avec le temps est le même que pour SQLite : yyyy-MM-dd HH:mm:ss.ffffff.
Ne pas oublier que PostgreSQL a un type pour les dates (DATE -> 2023-01-01) ou pour du temps (TIME -> HH:mm:ss)
Pour avoir plus de détails sur les formats de date : https://docs.postgresql.fr/11/datatype-datetime.html
Pour avoir la liste complète des fonctions sur les dates : https://www.postgresql.org/docs/current/functions-datetime.html
Ajouter et soustraire - DATE_ADD(), DATE_SUBTRACT()
Ces méthodes ajoutent ou de soustraient un intervalle de temps pour une date avec ou sans temps.
Voici la syntaxe.
DATE_ADD(date, INTERVAL 'valeur unité')DATE_SUBTRACT(date, INTERVAL 'valeur unité')
Voici les intervalles les plus utilisés pour les intervalles.
| Unité | Description |
|---|---|
MICROSECOND | Microsecondes |
SECOND | Secondes |
MINUTE | Minutes |
HOUR | Heures |
DAY | Jours |
WEEK | Semaines |
MONTH | Mois |
YEAR | Année |
Voici un exemple pour ajouter 8 jours à la date 2022-12-30.
SELECT DATE_ADD('2022-12-30', INTERVAL '8 DAY');--Réponse : 2023-01-07
Voici un exemple pour enlever 4 heures à la date 2022-12-30 02:30
SELECT DATE_SUBTRACT('2022-12-30 02:30', INTERVAL '4 HOUR');--Réponse 2022-12-29 22:30:00
Si l'on a juste une date seule, il est possible d'utiliser + ou - directement pour ajouter ou soustraire des jours. Sinon, on peut faire la même chose avec un intervalle
SELECT '2022-12-20'::DATE + 6;SELECT '2022-12-20'::DATE + INTERVAL 6 DAY;--Réponse : 2023-12-26SELECT '2022-12-20'::DATE - 6;SELECT '2022-12-20'::DATE - INTERVAL 6 DAY;--Réponse : 2023-12-14
::DATE est nécessaire pour préciser à PostgreSQL de gérer la chaîne de caractères comme une date. Ce n'est pas nécessaire, si l'on utilise une colonne qui a le type DATE comme date_naissance :
SELECT date_naissance + 6;
L'opérateur :: permet de forcer un type précis à une valeur (cast).
Pour la liste complète des fonctions sur les dates : https://www.postgresql.org/docs/current/functions-datetime.html
Date courante - CURRENT_DATE, CURRENT_TIME, CURRENT_TIMESTAMP
Il peut être pratique d'effectuer des requêtes en fonction du moment de l'exécution de la requête. Pour rendre ces requêtes réutilisables, il faut utiliser les valeurs ci-dessous :
CURRENT_DATE
Affiche la date en cours du système.CURRENT_TIME
Affiche l'heure en cours du système.CURRENT_TIMESTAMPouNOW
Affiche la date et l'heure en cours du système.
SELECT CURRENT_DATE AS DateActuelle, CURRENT_TIME AS HeureActuelle, CURRENT_TIMESTAMP AS DateAvecHeureActuelle
Ces valeurs sont généralement utilisées conjointement avec le DATE_ADD et DATE_SUBTRACT pour faire des comparaisons de dates.
Par exemple, il me faut les commandes des 10 derniers jours. Cette requête fonctionne, car il n'est pas possible d'avoir des commandes dans le futur.
SELECT *FROM CommandesWHERE DateCommande >= DATE_SUBTRACT(CURRENT_DATE, INTERVAL '10 DAY');
Séparer une date et l'heure - ::DATE, ::TIME
Pour séparer la portion date et heure d'une date de type (TIMESTAMP), il faut utiliser les convertions de type (cast) ::DATE et ::TIME.
SELECT '2022-11-07 19:23:29'::DATE AS LaDate, '2022-11-07 19:23:29'::TIME AS LHeure; --RésultatLaDate LHeure2022-11-07 19:23:29
Ceci peut être utile pour déterminer les ventes d'une journée, mais que le champ qui enregistre la date de la vente contient également l'heure.
SELECT *FROM VentesWHERE DateVente::DATE = CURRENT_DATE;
Partie d'une date - EXTRACT()
Il peut être pratique de décortiquer une date pour en extraire seulement une partie.
SELECT EXTRACT(YEAR FROM CURRENT_DATE) AS AnneeEnCours, EXTRACT(MONTH FROM CURRENT_DATE) AS MoisEnCours, EXTRACT(DAY FROM CURRENT_DATE) AS JourEnCours, EXTRACT(HOUR FROM CURRENT_DATE) AS HeureEnCours, EXTRACT(MINUTE FROM CURRENT_DATE) AS MinuteEnCours, EXTRACT(SECOND FROM CURRENT_DATE) AS SecondeEnCours
Il est possible de faire des agrégations avec les fonctions de dates. Par exemple, il faut connaître le nombre de ventes par mois.
SELECT EXTRACT(YEAR FROM DateVente) AS Annee, EXTRACT(MONTH FROM DateVente) AS Mois, SUM(Montant) AS MontantVenteFROM VentesGROUP BY EXTRACT(YEAR FROM DateVente), EXTRACT(MONTH FROM DateVente)ORDER BY EXTRACT(YEAR FROM DateVente), EXTRACT(MONTH FROM DateVente);
Différence entre deux dates
L'opérateur - permet de calculer la différence entre 2 dates. Cela génère un intervalle de temps. Il est possible de convertir dans une unité précise avec EXTRACT()`.
Voici quelques exemples.
SELECT EXTRACT(DAY FROM '2022-11-07 19:05:17'::TIMESTAMP - '2022-11-03 18:23:29') AS NbJour, EXTRACT(HOUR FROM '2022-11-07 19:05:17'::TIMESTAMP - '2022-11-03 18:23:29') AS NbHeure, EXTRACT(SECOND FROM '2022-11-07 19:05:17'::TIMESTAMP - '2022-11-03 18:23:29') AS NbSeconde, '2022-11-07 19:05:17'::TIMESTAMP - '2022-11-03 18:23:29' AS Intervalle; --RésultatNbJour NbHeure NbSeconde Intervalle4 96 348 108 4 days 00:41:48
À noter que si vous faites des calculs entre des dates sur la forme de texte, vous avez besoin de forcer un type seulement pour l'une ou l'autre des dates pour que PostgreSQL comprenne qu'on veut un calcul sur des dates.
Cette requête peut être utile pour connaître les réservations des 10 derniers jours. Il est possible d'avoir des réservations également dans le futur, mais il ne faut pas les avoir.
SELECT *FROM ReservationsWHERE EXTRACT(DAY FROM CURRENT_DATE - DateReservation) <= 10 AND EXTRACT(DAY FROM CURRENT_DATE - DateReservation) >= 0
La fonction AGE() permet de générer un intervalle à partir de la date d'aujourd'hui. Donc, on pourrait écrire la dernière requête comme cela avec AGE :
SELECT *FROM ReservationsWHERE AGE(DateReservation) <= INTERVAL '10 day' AGE(DateReservation) >= INTERVAL '0 day'
AGE() est intéressant principalement pour l'affichage dans un SELECT
Comparaison des dates avec et sans heure
Il est important de bien utiliser les méthodes des dates pour faire des requêtes.
Par exemple, si le champ contient la date et l'heure et qu'il faut obtenir les enregistrements du jour, il n'est pas possible de faire une vérification directe.
SELECT * FROM VentesWHERE DateHeureVente = CURRENT_TIMESTAMP;
Cette requête ne retournera rien, car la date 2022-11-07 12:19:56 n'égale pas 2022-11-07.
Même en spécifiant manuellement la date, la requête ci-dessous ne fonctionnera pas.
SELECT * FROM VentesWHERE DateHeureVente = '2022-11-07'
La date sans heure sera considérée comme l'heure 00:00:00. Donc la seule possibilité que les requêtes ci-dessus trouvent des enregistrements est qu'il à eu une vente à exactement 2022-11-07 00:00:00.
Il est donc important de transformer les dates correctement pour que les vérifications fonctionnent comme vous le désirez ou de choisir le bon type DATE ou TIMESTAMP si possible.
Exercices
Restauration BD
Importez le fichier sakila_postgres.sql dans votre pgAdmin. Le fichier se trouve sur LEA.
Utilisez la commande de restauration logique.
Requêtes
Effectuez les requêtes ci-dessous pour la base de données sakila et la table rental.
- Ajoutez 19 ans pour les champs rental_date et return_date.
a. Avec unSELECT
b. Avec unUPDATE - Enlevez 8 mois pour les champs rental_date et return_date.
a. Avec unSELECT
b. Avec unUPDATE - Ajoutez 13 jours pour les champs rental_date et return_date.
a. Avec unSELECT
b. Avec unUPDATE - Affichez tous les enregistrements qu'il y a eu plus de 5 jours entre la date de location (rental_date) et la date de retour (return_date).
- Affichez tous les enregistrements qui ont été loués aujourd'hui (rental_date).
- Affichez tous les enregistrements qui ont été loués (rental_date) dans les 25 derniers jours.
- Affichez le nombre de locations en fonction de l'année de location et par le mois de location (rental_date). Triez la liste par année et par mois.
- Supprimez toutes les locations qui sont dans le futur.
Solutions
Nous allons voir les solutions ensemble en classe.
Version originale par François St-Hilaire
Version modifiée en 2023 pour PostgreSQL par Pierre-Luc Boulanger